Challenge 1: Upload the data to the vector database
Introduction
This is one of the most complex challenges. This should take approximately 45 minutes.
The goal of this challenge is to insert the movie data, along with the vector embeddings into the database, under the table movies. Each movie’s data is stored along with a vector representation of its relevant fields in a row. When performing a vector search, the vector representing the search query sent to the db, and the db returns similar vectors. Along with these vectors, we ask Postgres to also send the other fields that are interesting to us (such as the movie title, actors, plot etc.).
This challenge includes creating an embedding per movie, and uploading the remainder of the metadata for each movie into each row. A row will look like this.
Vector; Title; Actors; Director; Plot; Release; Rating; Poster; tconst; Genre; Runtime
[0.1, 0.3, 0.56, ...]; The Kings Loss; Tom Hanks,Meryl Streep; Steven Spielberg; King Kong loses the tree his lives in and wants to plant a new one; 2001; 3.4; www.posterurl/poster.jpg; 128; Action,Comedy; 110 ...
You need to perform the following steps:
- Open the file dataset/movies_with_posters.csv and review it. This file contains the AI Generated movie details used in application.
- Select appropriate fields in the raw data for each movie that are useful to use in a vector search. These are factors users would typically use when looking for movies.
- Create an embedding per movie based on the fields you selected before.
- Upload each movie into the movies table. The schema is given below in the Description section. You might need to reformat some columns in the raw data to match the DB schema while uploading data to the db.
- Structure each entry (embedding and other fields) into the format required by the table.
Genkit Flows
Flows are like blueprints for specific AI tasks in Genkit. They define a sequence of actions, such as analyzing your words, searching a database, and generating a response. This structured approach helps the AI understand your requests and provide relevant information, similar to how a recipe guides a chef to create a dish. By breaking down complex tasks into smaller steps, flows make the AI more organized and efficient.
Key Differences from LangChain Chains:
While both flows and chains orchestrate AI operations, Genkit flows emphasize:
- Modularity: Flows are designed to be easily combined and reused like building blocks.
- Strong Typing: Clear input/output definitions help catch errors and improve code reliability.
- Visual Development: The Genkit UI provides a visual way to design and manage flows.
- Google Cloud Integration: Genkit works seamlessly with Google Cloud’s AI services.
If you’re familiar with LangChain, think of flows as Genkit’s counterpart with a focus on modularity and Google Cloud integration.
Pre-requisites
The setup should take approximately 15 minutes.
Open your project in the GCP console, and open a CloudShell Editor. This should open up a VSCode-like editor. Make it full screen if it isn’t already. If you developing locally, open up your IDE.
Step 1:
-
Clone the repo.
git clone https://github.com/MKand/movie-guru.git --branch ghack cd movie-guru
Step 2:
- Open a terminal from the editor (CloudShell Editor Hamburgermenu > terminal > new terminal).
-
Check if the basic tools we need are installed. Run the following command.
docker compose version - If it prints out a version number you are good to go.
Step 3:
-
Create a shared network for all the containers. We will be running containers across different docker compose files so we want to ensure the db is reachable to all of the containers.
docker network create db-shared-network - Setup the local Postgres database. This will create a pgvector instance, a db (fake-movies-db), 2 tables (movies, user_preferences), 2 users (main, minimal-user).
- Crucially, it also creates an hnsw index for the embedding column in the movies table.
Note
We create an index on our vector column (embedding) to speed up similarity searches. Without an index, the database would have to compare the query vector to every single vector in the table, which is not optimal. An index allows the database to quickly find the most similar vectors by organizing the data in a way that optimizes these comparisons. We chose the HNSW (Hierarchical Navigable Small World) index because it offers a good balance of speed and accuracy. Additionally, we use cosine similarity as the distance metric to compare the vectors, as it’s well-suited for text-based embeddings and focuses on the conceptual similarity of the text.
-
It also sets up adminer, lightweight tool for managing databases.
docker compose -f docker-compose-pgvector.yaml up -d
Step 4:
- Connect to the database.
- Go to http://locahost:8082 to open the adminer interface.
Note
If you are using the GCP CloudShell Editor, click on the webpreview button and change the port to 8082.
- Log in to the database using the following details:
- Username: main
- Password: mainpassword
-
Database: fake-movies-db
Step 5:
- Once logged in, you should see a button that says SQLCommand on the left hand pane. Click on it.
-
It should open an interface that looks like this:
-
Paste the following commands there and click Execute.
CREATE EXTENSION IF NOT EXISTS vector; CREATE TABLE IF NOT EXISTS movies ( tconst VARCHAR PRIMARY KEY, embedding VECTOR(768), title VARCHAR, runtime_mins INTEGER, genres VARCHAR, rating NUMERIC(3, 1), released INTEGER, actors VARCHAR, director VARCHAR, plot VARCHAR, poster VARCHAR, content VARCHAR ); CREATE INDEX ON movies USING hnsw (embedding vector_cosine_ops); CREATE TABLE user_preferences ( "user" VARCHAR(255) NOT NULL, preferences JSON NOT NULL, PRIMARY KEY ("user") ); GRANT SELECT ON movies TO "minimal-user"; GRANT SELECT, INSERT, UPDATE, DELETE ON user_preferences TO "minimal-user";
Step 6:
- Go to the project in the GCP console. Go to IAM > Service Accounts.
- Select the service account (movie-guru-chat-server-sa@##########.iam.gserviceaccount.com).
- Select Create a new JSON key.
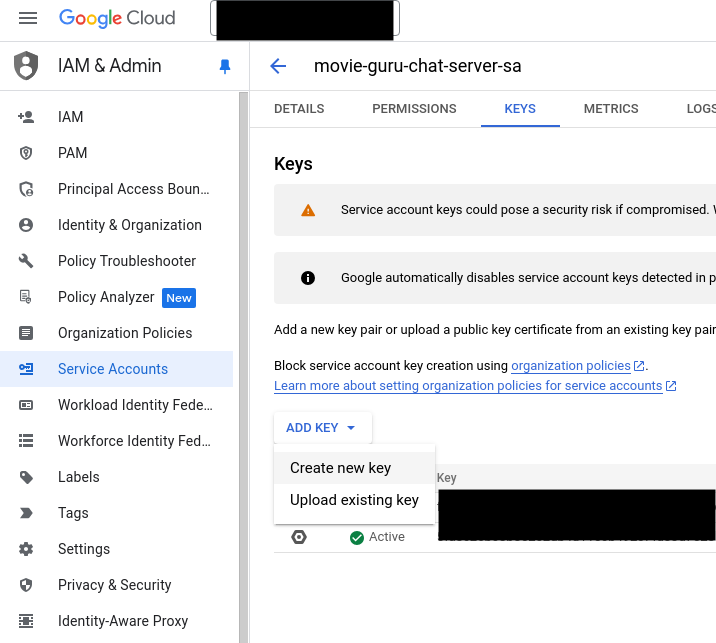
- Download the key and store it as .key.json in the root of this repo (make sure you use the filename exactly).
Note
In production it is BAD practice to store keys in file. Applications running in GoogleCloud use serviceaccounts attached to the platform to perform authentication. The setup used here is simply for convenience.
Step 7:
- Go to set_env_vars.sh.
-
You need to edit the first line in this file with the actual project id.
export PROJECT_ID="<enter project id>" -
Save the updated file and run the following command.
source set_env_vars.shNote
You will need to re-run this each time you execute something from a new terminal instance.
Now you are ready to start the challenges.
Description
The movies table has the following columns:
- rating: A numeric value from 0 to 5.
- released: An integer representing the year of release.
- runtime_mins: An integer.
- director: A character varying string, with each movie having a single director.
- plot: A character varying string.
- poster: A character varying string containing the URL of the poster.
- tconst: A character varying string serving as the movie ID, borrowed from IMDB (does not allow nulls).
- content: A character varying string.
- title: A character varying string.
- genres: A character varying string containing comma-separated genres.
- actors: A character varying string containing comma-separated actors.
- embedding: A user-defined data type to store vector embeddings of the movies.
You can do this exercise with GoLang or TypeScript. Refer to the specific sections on how to continue.
GoLang Indexer Flow
Look at the chat_server_go/pkg/flows/indexer.go file. This module is called by chat_server_go/cmd/indexer/main.go You’ll need to edit chat_server_go/pkg/flows/indexer.go file to upload the required data successfully. There are instructions and hints in the file to help you proceed.
- Once you think you have accomplished what you need to do, run the following command to start the indexer and let it upload data to the movies table.
-
You can always run it intermediately if you want to verify something.
docker compose -f docker-compose-indexer.yaml up indexer-go --build -
A successful uploading process should look like this:
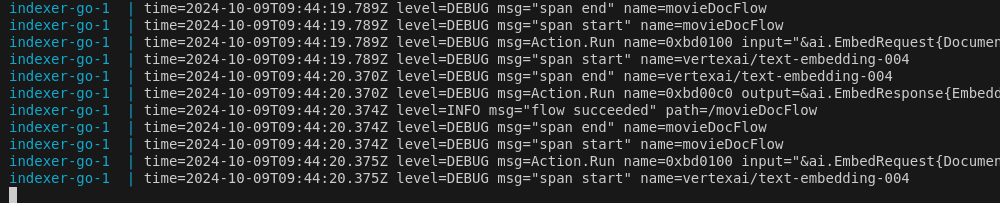
-
If at any point you want to clear the entire table, run the following command in adminer.
TRUNCATE TABLE movies; - If you are successful, there should be a total of 652 entries in the table.
-
Once finished, run the following command to close the indexer. You won’t need it anymore for other challenges.
docker compose -f docker-compose-indexer.yaml down indexer-go
TypeScript Indexer Flow
Look at the js/indexer/src/indexerFlow.ts file. You’ll need to edit it to upload the required data successfully. There are instructions and hints in the file to help you proceed.
-
Once you think you have accomplished what you need to do, run the following to start the indexer and let it upload data to the movies table. You can always run it intermediately if you want to verify something.
docker compose -f docker-compose-indexer.yaml up indexer-js --build -
Successful uploading process should look like this:
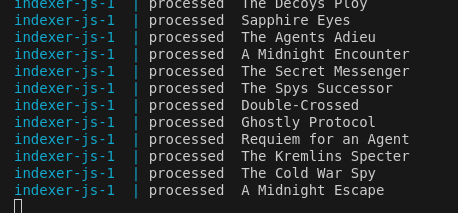
-
(OPTIONAL) If at any stage you want to clear the table because you made a mistake, you can run the following command in adminer.
TRUNCATE TABLE movies; - If you are successful, there should be a total of 652 entries in the table.
-
Once finished run the following command to close the indexer. You won’t need it anymore for other challenges.
docker compose -f docker-compose-indexer.yaml down indexer-js
Note
This process won’t exit automatically, but if you don’t see anymore movies being added, just check the database to see if all movies have been added.
Success Criteria
-
The movies table contains 652 entries. You can verify this by running the following command in the adminer:
SELECT COUNT(*) FROM "movies"; - Each entry should contain a vector embedding in the embedding field.
- The other fields in the schema should also be present and meaningful.