Challenge 7: Stay alert
Previous Challenge Next Challenge
Prerequisites
-
Run this command in the terminal (Cloud Shell terminal). This simulates your app team making some changes to the app.
## Check if the METRICS_APP_ADDRESS env variable is set in your environment before you do this. curl -X POST \ -H "Content-Type: application/json" \ -d '{ "ChatSuccess": 0.95, "ChatSafetyIssue": 0.1, "ChatEngaged": 0.40, "ChatAcknowledged": 0.10, "ChatRejected": 0.45, "ChatUnclassified": 0.05, "ChatSPositive": 0.6, "ChatSNegative": 0.1, "ChatSNeutral": 0.2, "ChatSUnclassified": 0.1, "LoginSuccess": 0.999, "StartupSuccess": 0.95, "PrefUpdateSuccess": 0.99, "PrefGetSuccess": 0.999, "LoginLatencyMinMS": 10, "LoginLatencyMaxMS": 200, "ChatLatencyMinMS": 4500, "ChatLatencyMaxMS": 8000, "StartupLatencyMinMS": 400, "StartupLatencyMaxMS": 1000, "PrefGetLatencyMinMS": 153, "PrefGetLatencyMaxMS": 348, "PrefUpdateLatencyMinMS": 363, "PrefUpdateLatencyMaxMS": 645 }' \ $METRICS_APP_ADDRESS/phase
Introduction
This challenge guides you through monitoring the four SLOs created in the previous challenge.
- The devs have pushed a change: You’ve learnt that the app team just made a change to the backend a short while ago.
-
Perform an Initial Observation of the SLOs: Initially, all Service Level Indicators (SLIs) should be within the acceptable range of the objective. Minor, short-term dips below the objective are normal and not a cause for concern, as long as the SLO is met within the specified compliance window.
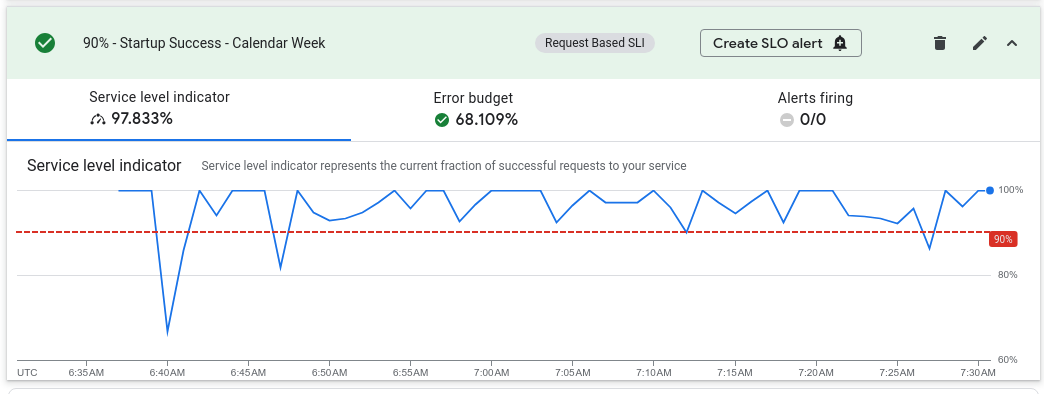
Description
- View the Error Budget (EB) charts for each SLO.
- Create Burn Rate Alerts
- Create SLO alerts from the UI for all 4 SLOs.
- Slow burn rate alert (1.5-2.0x): Indicates minor issues or gradual degradation.
- Fast burn rate alert (10x): Signals major outages requiring immediate attention.
Warning
Alerts may not trigger in this lab! The lab starts with poor SLI performance, which consumes the error budget almost immediately. The alert window is therefore very brief and may have passed before you reach this step.
- Create SLO alerts from the UI for all 4 SLOs.
- Observe burn rates for different SLOs:
- Keep an eye on the burn rates for the 4 SLOs for 5-10 minutes.
- Has the recent app change introduced any issues. If so, where?
- Estimate the burn rate for each SLO and identify which ones require immediate action.
- What would an ideal burn rate be?
Success Criteria
- Burn Rate Triggers: Ensure you have created 2 burn rate alerts for all your SLOs (8 in total).
- These alerts should be configured to trigger at different burn rates (e.g., 1.5-2.0x for slow burn, 10x for fast burn) to capture varying levels of degradation.
- You are able to eyeball the error budget change rate of all the SLOs.
- You’ve identified 2 SLOs with decling error budgets where one is declining very rapidly, while the other is declining more slowly.
- [Optional] Alert Activity: While the exact number of alerts triggered will vary depending on the system’s behavior, may see a few alerts. Don’t be disappointed if you don’t.
Learning Resources
What are error budgets
An error budget is the acceptable amount of time your service can fail to meet its SLOs, helping you balance innovation and reliability. Calculated as 1 - SLO, a 99% availability SLO gives you a 1% error budget (about 7.3 hours per month) for new features, maintenance, and experimentation. Error budgets promote proactive risk management and informed decision-making about service reliability.
What is a burn rate
Burn rate measures how quickly you’re using up your error budget. It acts as an early warning system for SLO violations, helping you prioritize and respond to issues before they impact users. Calculated as a multiple of your error budget consumption, a high burn rate (e.g., 10x) signals a major problem needing immediate action. A slow burn rate (generally configured over a longer interval) alerts you if you are likely to exhaust your error budget before the end of the compliance period. It is less urgent than a fast burn, but signals something may be wrong, but not urgent. Setting alerts for different burn rates (e.g., 2x for slow burn, 10x for fast burn) allows you to proactively manage service reliability and keep users happy. By monitoring burn rate, you can ensure your services meet their SLOs and avoid “overspending” your error budget.
- If there were no issues, or planned maintainence events and everything operated perfectly, the error budget would remain at 100%.
- A healthy burn rate is beneficial, indicating that you are utilizing your error budgets effectively for improvements and planned maintenance. If you error budget is consistently near 100% at the end of the compliance period, then you’re likely wasting these windows.
- A burn rate of 1x means that your error budget will be fully consumed by the end of the compliance period.
- While you established the SLOs in Challenge 5, it’s important to note that the error budgets are calculated from the beginning of the lab, as metrics collection commenced in Challenge 1.