Disneyland Agentic Data Cloud
Introduction
Welcome, Disney Data Wizards! 🪄
Planning the perfect Disneyland trip is a complex optimization problem. Visitors want to maximize magic and minimize waiting. They want to know: Which rides are best suited for them? When are the crowds thinnest? What is the optimal route through the park to avoid bottleneck queues?
In this gHack, your mission is to transform raw data—visitor reviews, attraction catalogs, historical wait times, park brochures, and visitor movement logs—into an end-to-end, intelligent guest assistance system.
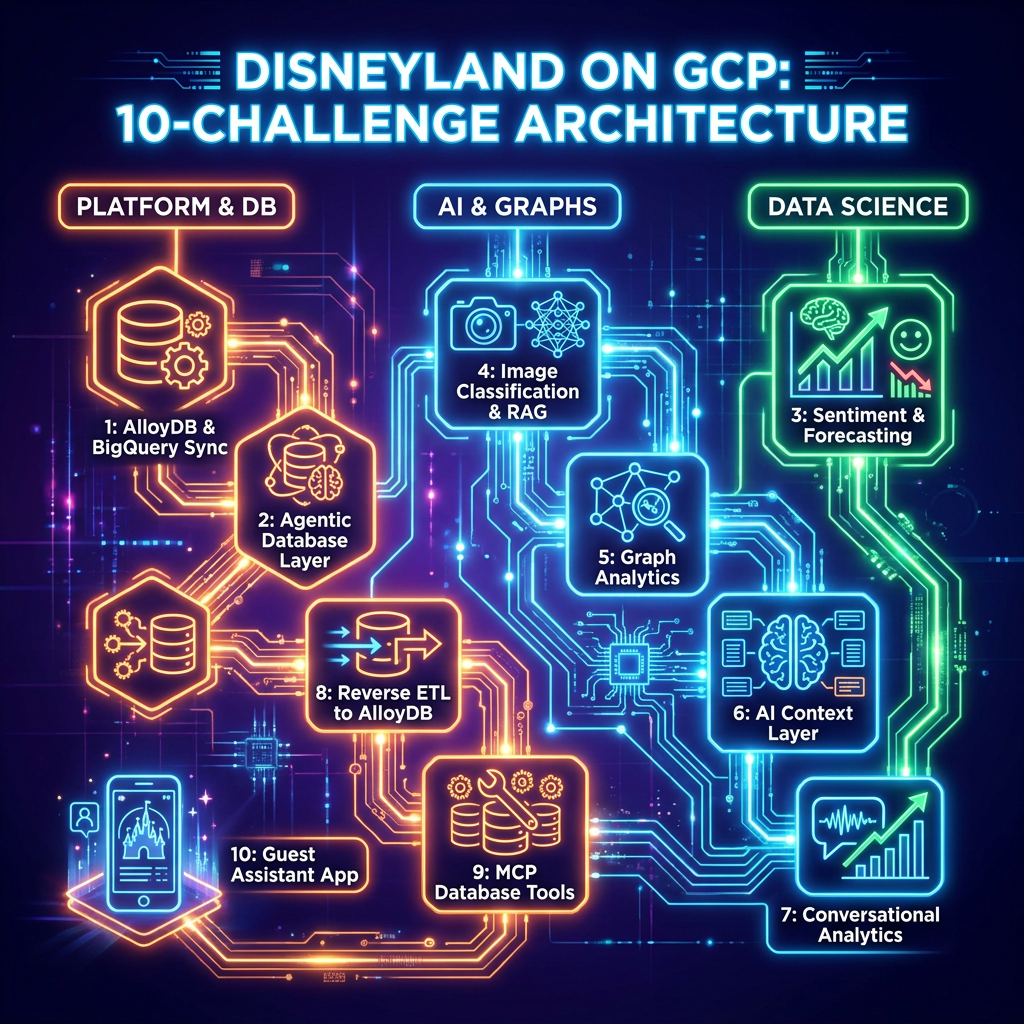
This gHack is designed to be highly challenging and is structured into 10 challenges that can be parallelized across 3 key team personas to optimize development speed:
- DB & Platform Engineers will build the operational database in AlloyDB, configure Datastream replication, set up the database agentic layer, sync analytical insights, and assemble the final agent and web UI (Challenges 1, 2, 8, 9, and 10).
- Data Scientists & Analysts will train predictive models, perform sentiment analysis, cluster attractions in BigQuery, and design the semantic layer/Conversational Analytics agent for park managers (Challenges 3, 6, and 7).
- AI & Graph Engineers will construct RAG pipelines, classify multimodal images, and model/query visitor movement patterns using property graphs in BigQuery (Challenges 4 and 5).
Get ready to build an agentic data pipeline that would make Mickey proud! Let the magic begin! ✨
Learning objectives
In this hack, you will build an end-to-end data pipeline with AI and database capabilities on Google Cloud:
- AlloyDB AI: Ingest operational data and generate vector embeddings natively.
- Real-time replication: Set up CDC from AlloyDB to BigQuery using Datastream.
- Agentic database: Configure predictable SQL generation in AlloyDB and expose it as tools.
- Predictive analytics: Train forecasting and sentiment models using BigQuery ML.
- Multimodal RAG: Build image classification and PDF search pipelines.
- Graph analysis: Map visitor movements and query patterns using GQL.
- Context layer (Knowledge Catalog): Build a centralized metadata context layer, business glossary, and profiling rules.
- Conversational analytics: Build a natural language assistant using BigQuery Studio.
- AlloyDB sync: Copy insights back to AlloyDB using FDW for fast serving.
- MCP tools: Expose database capabilities using the MCP Toolbox.
- App deployment: Build a web app with the ADK and deploy it locally.
Challenges
- Challenge 1: Setting up AlloyDB and replicating data to BigQuery
- Challenge 2: Creating the agentic database layer
- Challenge 3: Sentiment and wait-time forecasting
- Challenge 4: Image classification and brochure RAG
- Challenge 5: Graph analytics and visitor flow
- Challenge 6: Preparing the Context Layer
- Challenge 7: Conversational analytics for insights
- Challenge 8: From insights to action, syncing BigQuery and AlloyDB
- Challenge 9: Exposing Database Tools via MCP
- Challenge 10: Building the guest assistant app
Prerequisites
- Basic knowledge of Google Cloud services (AlloyDB, BigQuery, Datastream)
- Intermediate knowledge of SQL and PostgreSQL
- Basic familiarity with Python and Agentic AI concepts (MCP, ADK)
- Access to a Google Cloud project with the necessary APIs and resources provisioned
Contributors
- Matt Cornillon
- Rayhane Rezgui
👥 Team Roles & Parallelization Paths
This gHack is designed to be highly challenging but is fully parallelizable across different team members. Whether you are a team of 2, 5, or more, you can split the challenges to build in parallel and assemble a complete intelligent system in under 4 hours.
📊 Recommended Parallelization Options
Here is how you can divide and conquer based on your team size:

🧩 Option 1: The 3-Group Split (Recommended)
- Group A (Platform & DB Engineers): Focuses on the core transactional and serving loop.
- Path: Challenge 1 -> Challenge 2 -> Challenge 8 -> Challenge 9 -> Challenge 10
- Group B (Data Scientists): Focuses on analytics, forecasting, and clustering.
- Path: Challenge 3 -> Assist Group C with Challenge 7 or Group A with Challenge 10
- Group C (AI & Graph Engineers): Focuses on unstructured data, graphs, and internal conversational search.
- Path: Challenge 4 -> Challenge 5 -> Challenge 6 -> Challenge 7
👥 Option 2: The 2-Group Split
- Group A (Database & Application Developers): Focuses on database setup, agentic tool serving, and app integration.
- Path: Challenge 1 -> Challenge 2 -> Challenge 8 -> Challenge 9 -> Challenge 10
- Group B (AI, ML & Analytics Engineers): Focuses on all BigQuery-centric analytics, ML models, RAG, and property graphs.
- Path: Challenge 4 -> Challenge 3 -> Challenge 5 -> Challenge 6 -> Challenge 7