Open Lakehouse with Apache Iceberg
Introduction
Welcome to DataFuture Corp. We are officially transitioning from our legacy data warehousing solution to a modern, open Data Lakehouse architecture. Our goal is to achieve the high-performance analytics typical of BigQuery while maintaining the flexibility of open standards. This ensures that diverse engines—such as Spark and Trino—can access a single source of truth simultaneously, eliminating the need for costly data duplication.
We have selected Apache Iceberg as our foundational table format. It provides the enterprise-grade features we require, including:
- ACID Transactions: Ensuring data integrity across concurrent writes.
- Schema Evolution: Modifying tables without breaking downstream queries.
- Time Travel: Querying historical snapshots for audits or rollbacks.
- AI Readiness: Seamlessly integrating with machine learning workflows by providing high-performance data fetches for model training and supporting vectorized reads for AI-driven analytics.
Your team is tasked with building the bedrock of this platform on Google Cloud. You will begin by configuring the storage layer and conclude by demonstrating true multi-engine and AI interoperability.
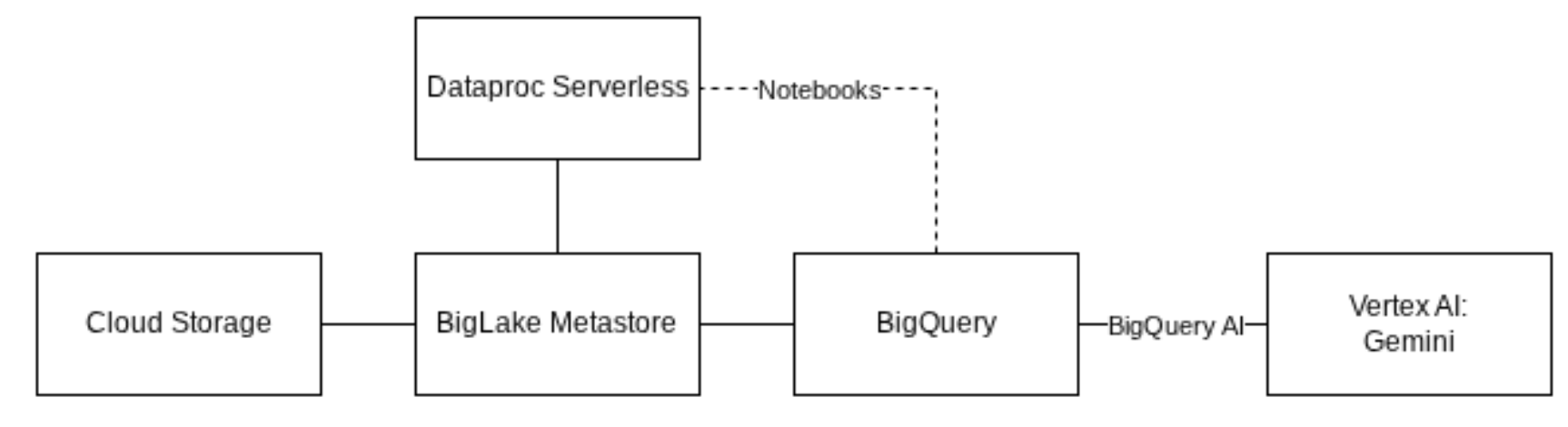 Architecture diagram for the challengesi in this gHack.
Architecture diagram for the challengesi in this gHack.
Learning Objectives
This hack will help you explore the following tasks:
- Configuring BigLake for open table formats
- Creating and managing Iceberg tables using BigQuery
- Performing DML operations (ACID transactions) on Iceberg tables
- Utilizing time travel for historical data analysis
- Managing security with fine-grained access control
- Interacting with Iceberg tables using Dataproc (Spark)
- Integrating Iceberg data directly with Gemini models for AI use cases
Challenges
- Challenge 1: The open foundation
- Challenge 2: Data interoperability across Lakehouse
- Challenge 3: Schema evolution and time travel
- Challenge 4: Fine-grained access control
- Challenge 5: Multi-engine polyglot
- Challenge 6: AI with multi-modal analysis
Prerequisites
- Basic knowledge of Google Cloud Platform (BigQuery, Cloud Storage)
- Basic knowledge of SQL
- Basic understanding of Python/Spark is helpful but not mandatory
Contributors
- Peter Bavinck
- Steve Loh
- Kelly Vehent